作者:Dongyu Liu, Panpan Xu, and Liu Ren
发表:IEEE VAST 2018
简介
多维时空数据可视化常用的方式是在不同视图中对不同维度上的值做聚合,用户可以在不同的视图中,通过刷选、连线,实现查询、选择、高亮等操作。这种方法的可扩展性往往受到数据维度及数据量的影响,解决方案有以数据立方体的形式存贮数据、GPU 并行计算等等。但是,这种方法难以在子数据集上找到隐藏的模式,例如,工作日与双休日的数据模式可能是不同的,但在没有先验假设的情况下,这些视图很难将用户引导向某种数据子集的选择方式。此外,这种方法还需要数据分析员进行繁杂的手动工作。 因此,本文提出了一种基于张量分解的大规模时空数据的模式自动化提取与可视分析方法,本文的主要贡献如下:
分段的秩一张量分解算法
支持逐渐划分与 level-of-detail 探索的多维时空数据可视分析框架
三个横跨多领域与分析任务的真实数据集案例
符号介绍
张量:三维及以上数组
符号定义:
m 维张量
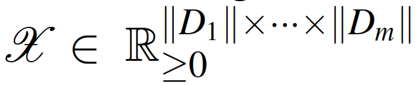
向量外积
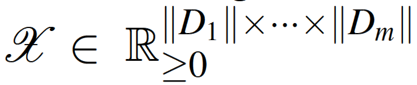
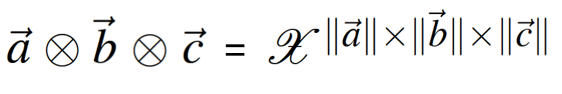
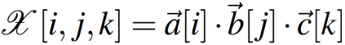
- 秩一张量:能表示为向量外积的张量

- 其他符号
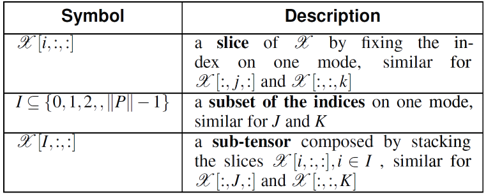
张量建模
张量分解
文章所用的张量分解方法为秩一张量的 CP 分解,算法伪代码如下:

其中,每轮迭代需要优化以下的损失函数:

迭代停止的条件为达到指定迭代步数或相邻两轮的差值小于指定阈值。
分段张量分解
但是刚刚提出的张量 CP 分解方法并不能完全捕获数据中的变化,比如工作日跟双休日的模式不同。因此本文在此基础上提出了分段分解,即在张量的某些维度进行划分,将其分为若干子张量,再进行分解。
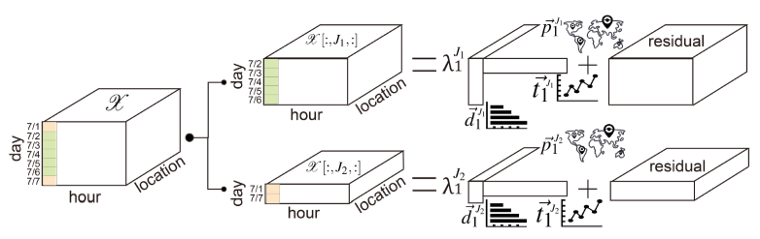
划分算法的伪代码如下(以日期作为划分维度为例):

设计需求
作者共邀请了 4 位来自 2 个完全不同的应用领域的专家,提出了对多维时空数据分析的通用需求:
展示多个维度的潜在模式
实现对比分析
将提取模式与原始数据的偏离度可视化
实现可操纵的数据划分与聚类
支持划分历史的溯源
可视化设计
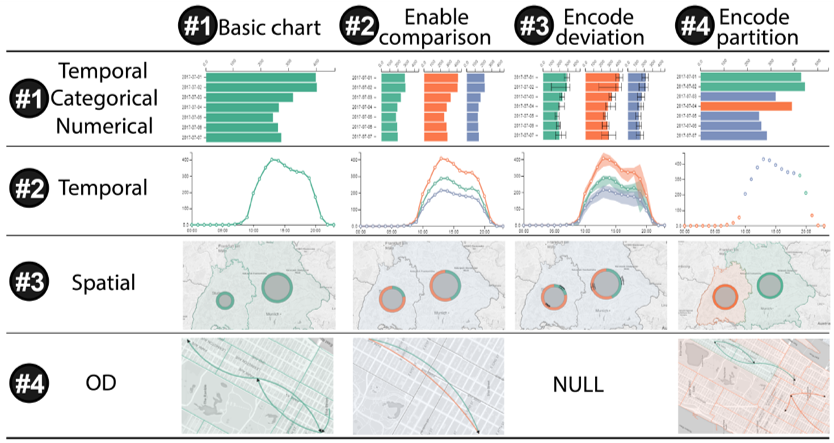
文章首先选择了一系列不同的基础可视化图表对不同维度上的数据进行表示(第一列)。其次,采用 Juxtaposition 和 Superposition 的方式使得多个基础图表可以进行对比(第二例)。并计算分解得到的近似张量与原始张量的偏差值百分比,并将偏差值的四分位数以类似盒须图的形式编码在基础图表中(第三列)。对张量进行划分后,每个划分用不同的颜色映射在基础图表中(第四列)。本文的可视化界面如下:
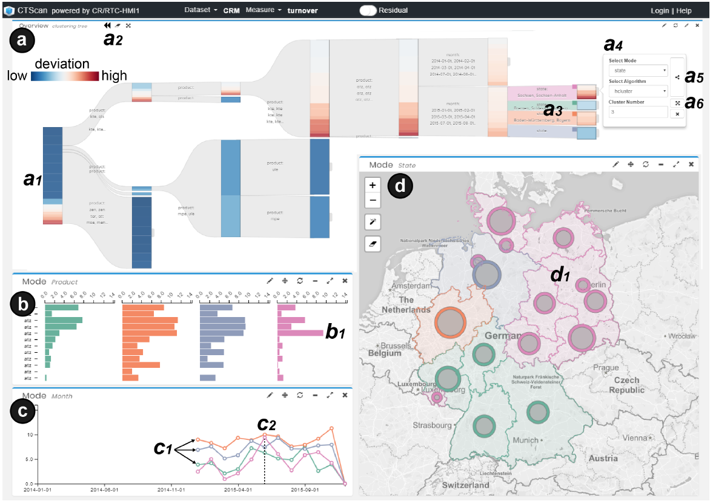
用户通过最上方的树图对张量进行划分,根节点表示原始张量,节点和连线的高度表示张量中所有项的和。每个被选择的节点前面都会有一个小的正方形,其颜色用以标记类别,与其他视图中保持一致。当鼠标 hover 到节点上时,会出现划分的功能面板,用户可以在面板中选择划分的维度、聚类算法、聚类数量。每个节点的颜色表示近似张量与原始张量的偏差值。
算法评估
对一个 p 维数据集,每个维度的长度为 n,算法的复杂度为 O(n^p)。测试服务器的配置为 2.20GHz Intel i7-6650U CPU, 16GB RAM,计算三维百万级数据需要的时间小于 1s,计算思维百万级数据需要的时间小于 10s。同时,通过与一个 baseline 方法进行比较,做了定量测试。Baseline 方法将张量在某个维度的切片转化为向量,对这些向量进行聚类,得到一个划分。在合成数据集上,使用 ARI 指数评估聚类结构之间的相似度,本文方法表现的比 baseline 方法好;在真实数据集中,用一个代价函数评估划分后得到的结果与原始数据的偏差,也是本文的方法表现的较好。

文章总结
1.在数据量大时算法的效率不高
2.由于文章用颜色划分类别,因此划分类别的数量局限于一打
3.部分可视化图表不支持过多元素,且不同视图中间缺乏时空关联性
4.对多维时空数据的聚合只用到了加法,无法支持其他的聚合方式(例如求最大值、求平均值等)
✉️ zhangtianye1026@zju.edu.cn